7月7日,在第四届circRNA论坛正火热进行中,一个重磅级的好消息传来:整合的人类环状RNA的数据库circBank正式上线了!数据库网址:http://www.circbank.cn/
图1 circBank数据库首页
数据库总体情况
circBank数据库共收录了140790条人类circRNA的记录,每一条circRNA记录都单独做了一个详细信息的页面。针对每个circRNA的信息主要包括:该circRNA的详细序列;在小鼠中同源性较高的circRNA及其对应的序列;miRNA结合的预测分析;ORF预测分析;COSMIC记录的突变和多态性位点汇总;m6A修饰信息。由于miRNA预测的结合位点数据比较庞大,因此单独做了一个展示的页面,页面中的记录按照打分高低的顺序列出。
circBank数据库还专门开发了一套专用的ID号。相信众位同行一定会有个苦恼的问题,就是目前circRNA的命名太混乱了,直接用Host gene的名字也不很妥当,因为每个基因所对应的circRNA太多了。circBase的ID号虽然应用比较广泛,但这个号码的信息量太少,很难记住更不利于口头交流。有鉴于此,我们开发了一个全新的ID号,该ID号基于对应的Host gene的名字和所对应的位置,具体的规则下面有详述。
circBank数据库提供了多种检索窗口,可以直接在首页中输入相应信息后实现快速检索,也可以在 “circRNA”和“miRNA”两个菜单中分别进行高级检索。为了方便同行交流,数据库也开辟了数据上传的窗口,欢迎同行们给数据库上传所发现的新的circRNA,我们将会有针对性的对数据库版本进行更新。
如何在circBank中检索?
circBank数据库给出了多个检索的渠道。包括首页的快速检索,“circRNA”和“miRNA”两个菜单中的高级检索。
首页的快速检索窗口可以通过circBank ID号,circBase数据库的ID号以及Host gene的Symbol或Ref-seq number进行快速检索。以HIPK3为例,首页的快速检索可以用如下的格式进行检索:“has_circHIPK3_001”、“has_circ_0021592”、“HIPK3”、“NM_005734”四种格式进行检索。
在circRNA检索菜单,可以通过基因名称(Gene Symbol)、circBank ID、cirBase ID等关键词分别检索。与此同时,还可以设置保守性、m6A修饰及ORF预测等过滤条件。
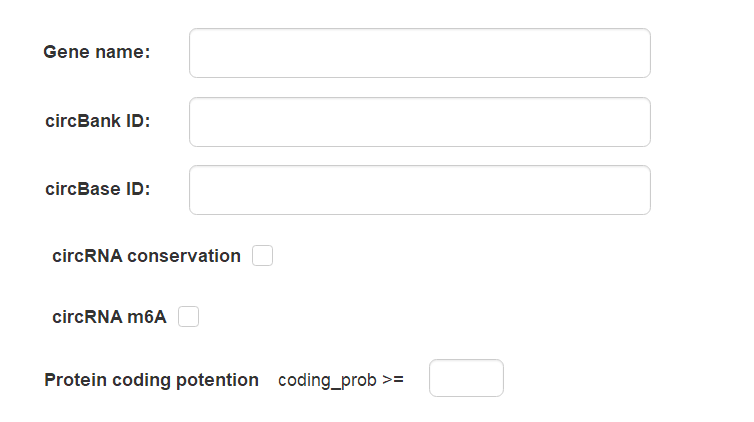
图2 circRNA高级检索窗口
在“miRNA”检索菜单下,可以通过miRNA ID、circBank ID、cirBase ID等关键词分别检索。也可以设置保守性、m6A修饰及ORF预测等过滤条件。
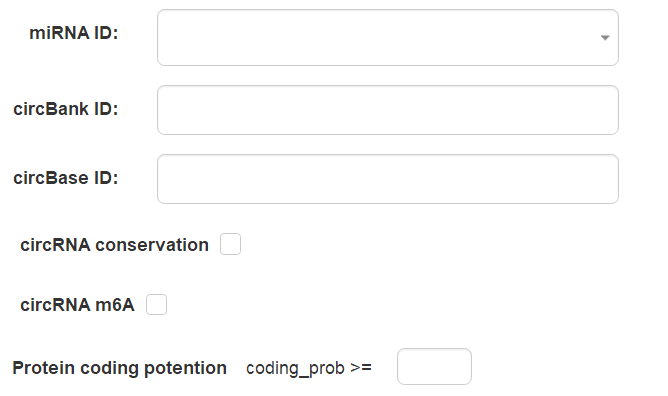
图3 miRNA高级检索窗口
单个circRNA记录页的信息有哪些?
以HIPK3为例,通过检索窗口可以得到如下的结果:
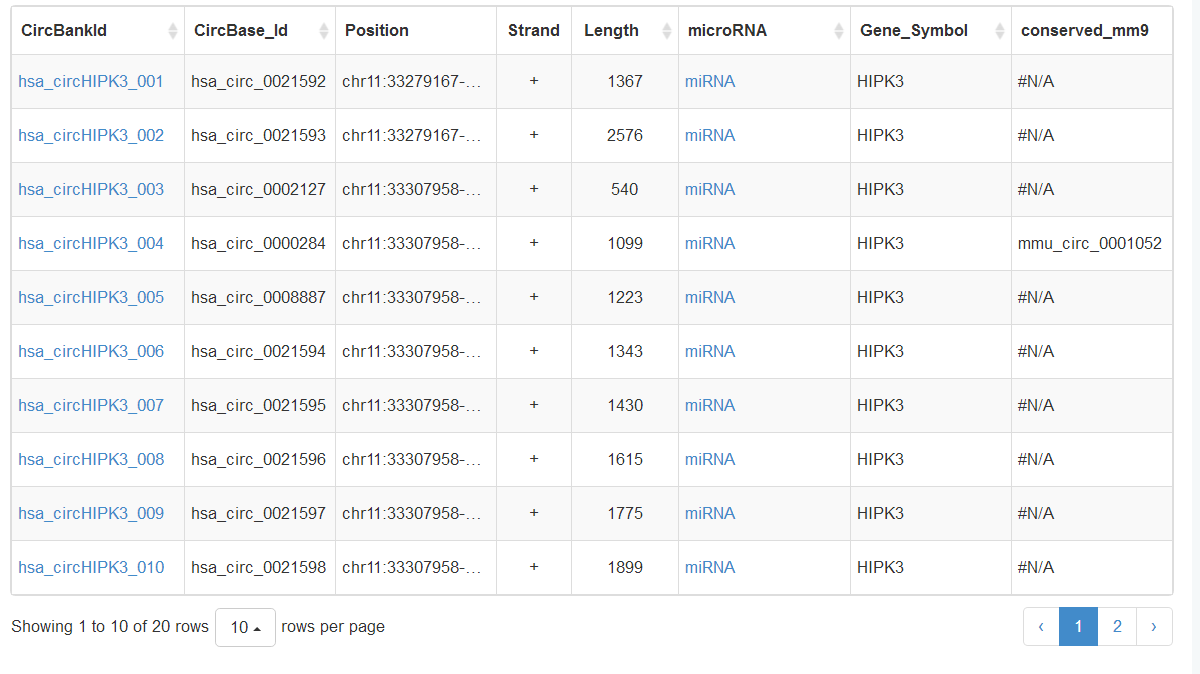
图4 HIPK3检索页面
检索结果显示,数据库共收录了20条HIPK3相关的circRNA记录。显示蓝色的部分点击之后会连接进入对应的页面。以“hsa_circHIPK3_004”为例,左侧“hsa_circHIPK3_004”的地方会跳至该circRNA的信息页面:
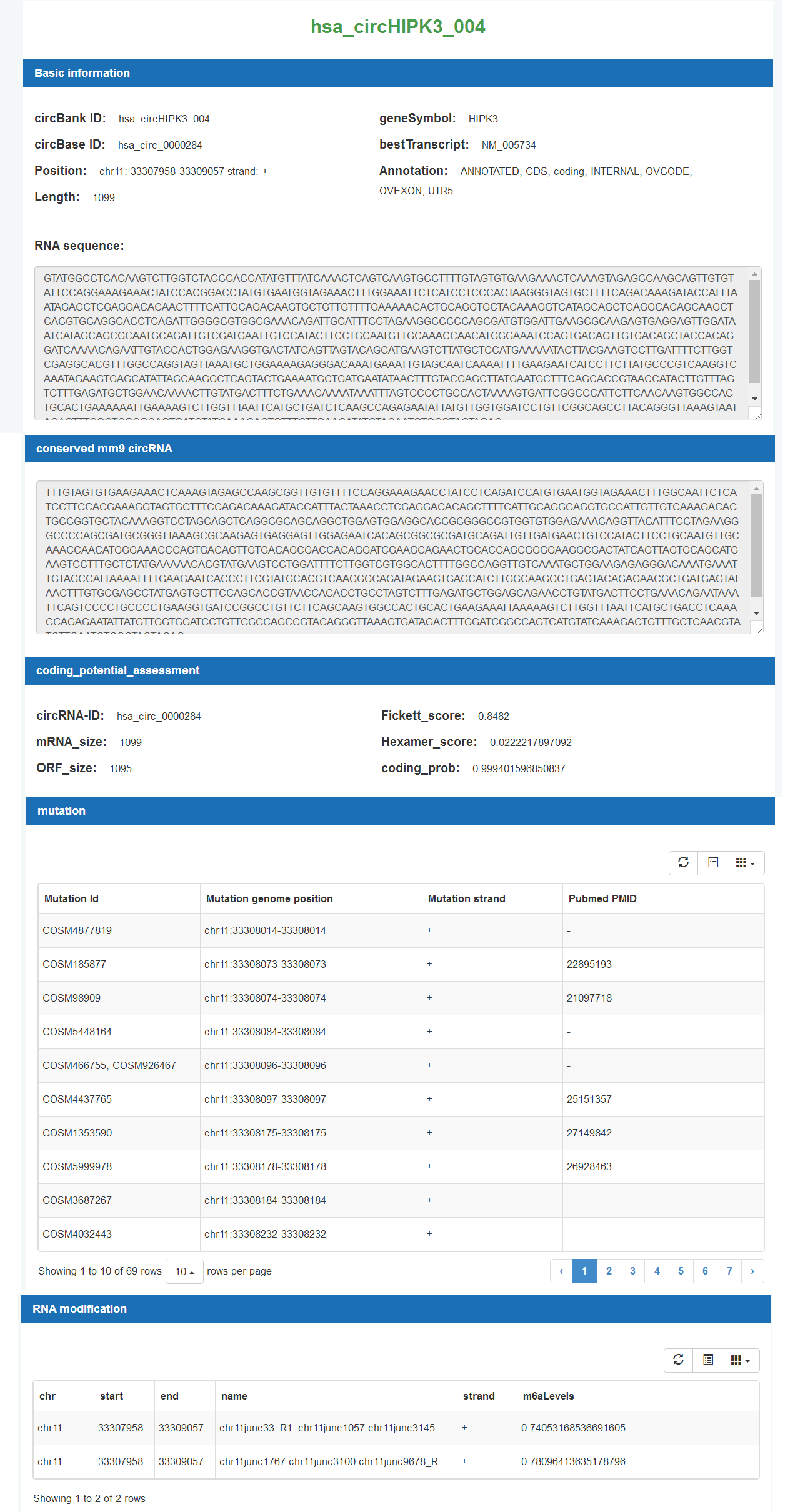
图5 circHIPK3_004信息页面
可以分别看到该circRNA的详细序列,小鼠中保守的circRNA和对应的序列,ORF预测打分的情况,COSMIC收录的突变和多态性信息,m6A修饰的信息。
如果点击检索页面中每一行对应的miRNA的蓝色标志,会跳至该circRNA预测分析所得的miRNA结合的情况。
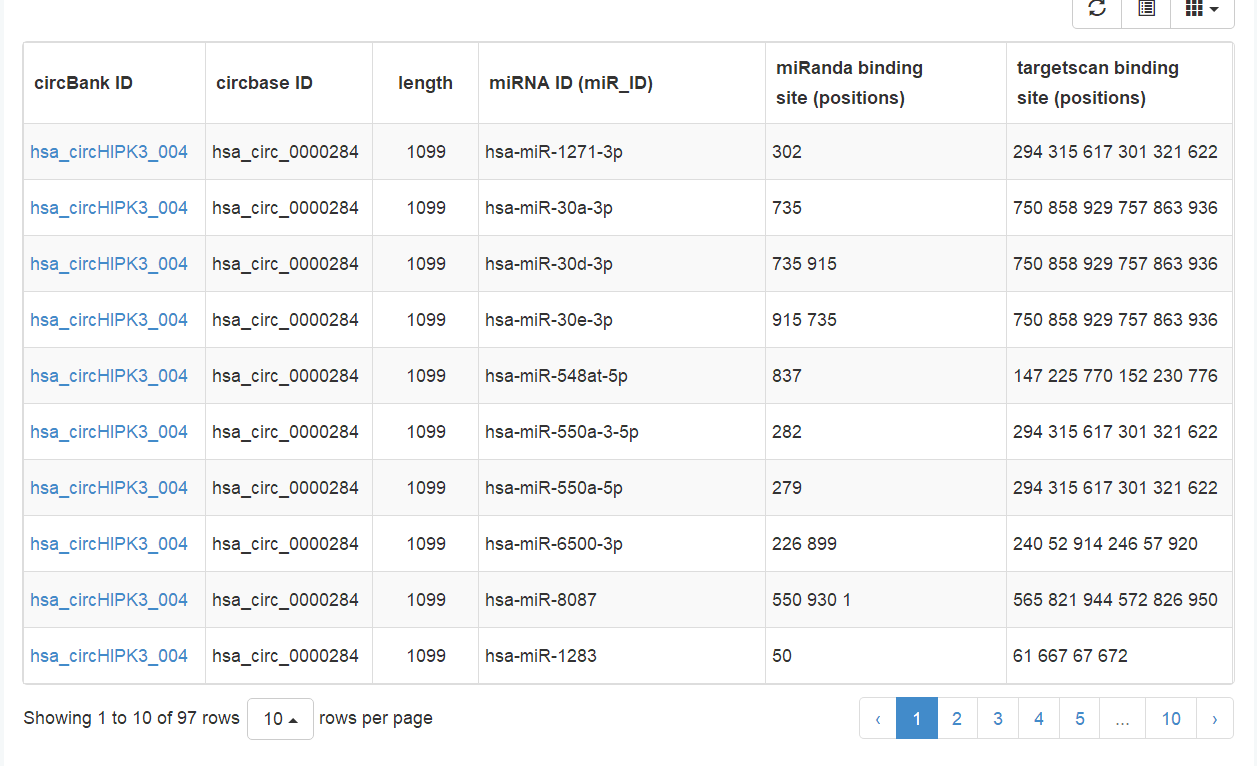
图6 hsa_circHIPK3_004预测miRNA的情况
对应于hsa_circHIPK3_004,一共预测到97种可能结合的miRNA分子,排列的顺序按照Miranda和targetscan工具打分的情况,打分高的靠前排列。结合保守性,ORF,突变信息及m6A修饰等信息,方便使用者快速锁定更有价值的分子。
circBank数据库还给出了直接用miRNA ID进行检索的功能,可以分析感兴趣的miRNA可能结合哪些circRNA分子。以hsa-miR-1283为例,检索结果如下:
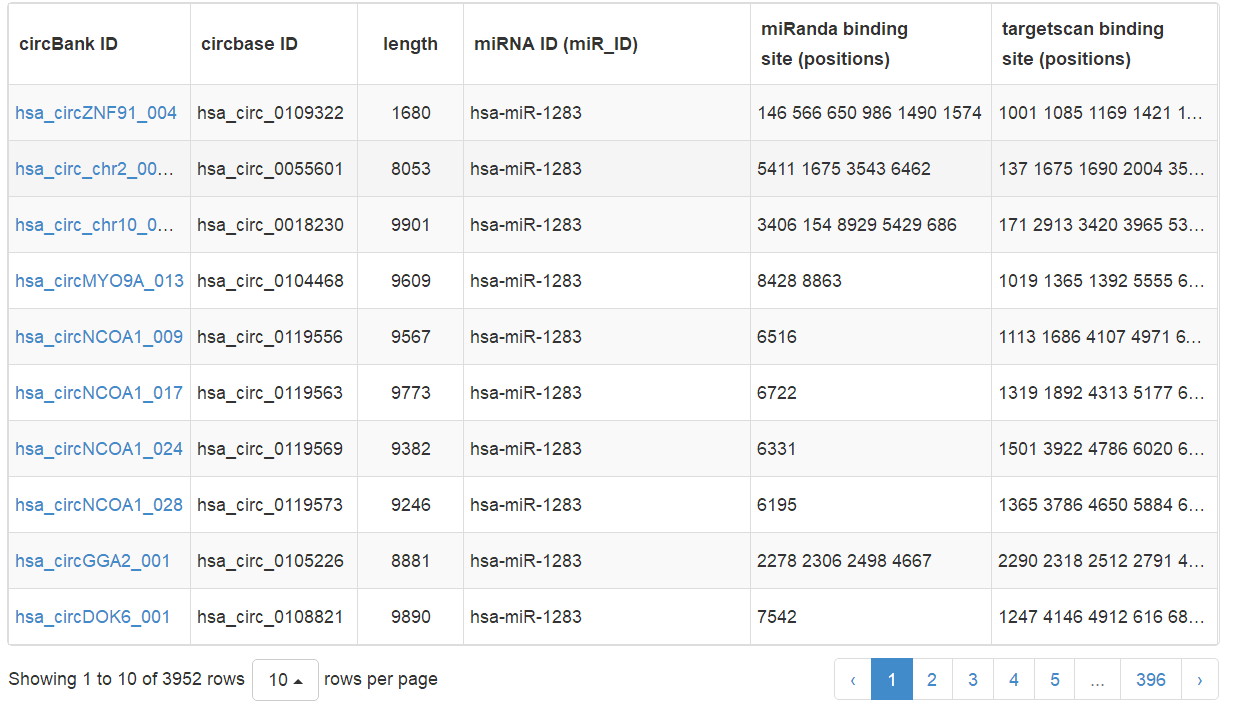
图7 miRNA ID检索结果
circBank中circRNA的ID号规则是怎样的?
我们在circBank数据库中针对每个circRNA分子构建了全新的ID号,该ID号的格式如下:
hsa_circA_001
其中“hsa”是人类来源的意思,circA代表了从“A”基因来源的circRNA,末尾的数字是根据该circRNA在Host gene中对应的位置排序得到的。还是以HIPK3基因为例,该基因对应的circRNA记录共有20条,前面的名称都是“hsa_circHIPK3_xxx”,最后的三位数是依据所有circRNA在HIPK3基因中对应的位置排序得到的,排序的规则是:先看起始位点,再看终止位点。起始位点越靠近前端(5’端)的排血越靠前,起点一致的看终止位点,终止位点越靠前的排序越靠前。示意图如下图:
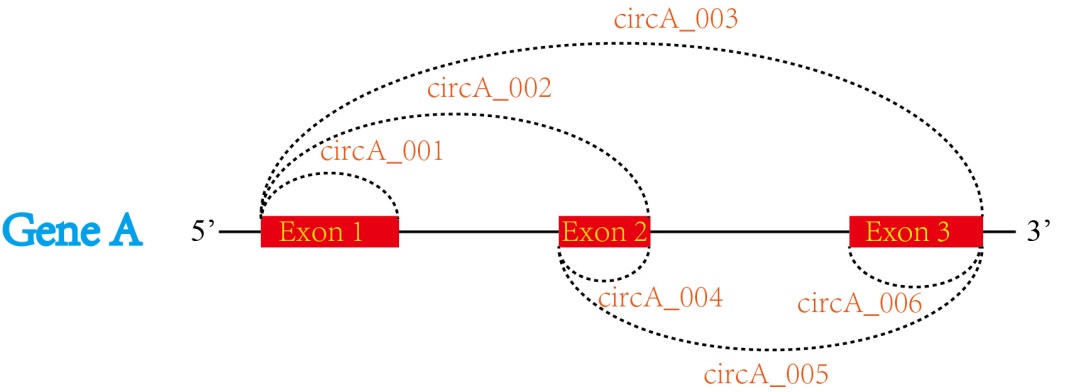
图8 circBank ID号生成规则概述
如果起始位点和终止位点一致的,可以认为是可变剪切的情况,命名规则为在上述ID的基础上增加一层编号,编号的原则按照可变剪切的大小,长度越短的编号越小。可变剪切编号格式如下:
hsa_circA_001_V01
所有circRNA的ID号在正式公布的数据库中永久不变。这样就存在一个后面发现的circRNA的ID号会跟已有的ID号冲突的问题,解决的办法是新录入的circRNA一定要在原有编号的基础上增加,新增的circRNA的ID号也按照相同的规则依次排列,一旦正式更新数据库后就确定下来,不再变更。
针对没有mapping到已知基因(包括lncRNA)的circRNA记录,根据在标准基因组中的参考坐标从小到大排列,命名格式暂用所在的染色体代替gene symbol。格式如下:hsa_circChrom1_001
对于融合基因的circRNA,对应的gene symbol由融合后基因的名称取代,如来源于BCR-Abl融合基因的circRNA如果不是跨越融合位点的,按照各自host gene编号,跨越融合位点的按照“hsa_circBCRAbl_001”的格式编号,其他规则同前。
circBank数据库的维护和数据上传
为方便同行的交流,适应不断发展的circRNA研究进展,我们会针对新发表或用户上传的数据进行数据更新。数据库的日常维护由密码子基因公司承担,数据上传后也由相关的工作人员进行数据的整理。